AI 技术翻译
上一篇写 Worse Is Better 时,我提到最近想系统补一轮计算机科学和软件架构经典。
问题是,这些经典大多是英文。我不是完全读不懂,但读得慢。慢到读一篇论文之前,先要做半天心理建设。
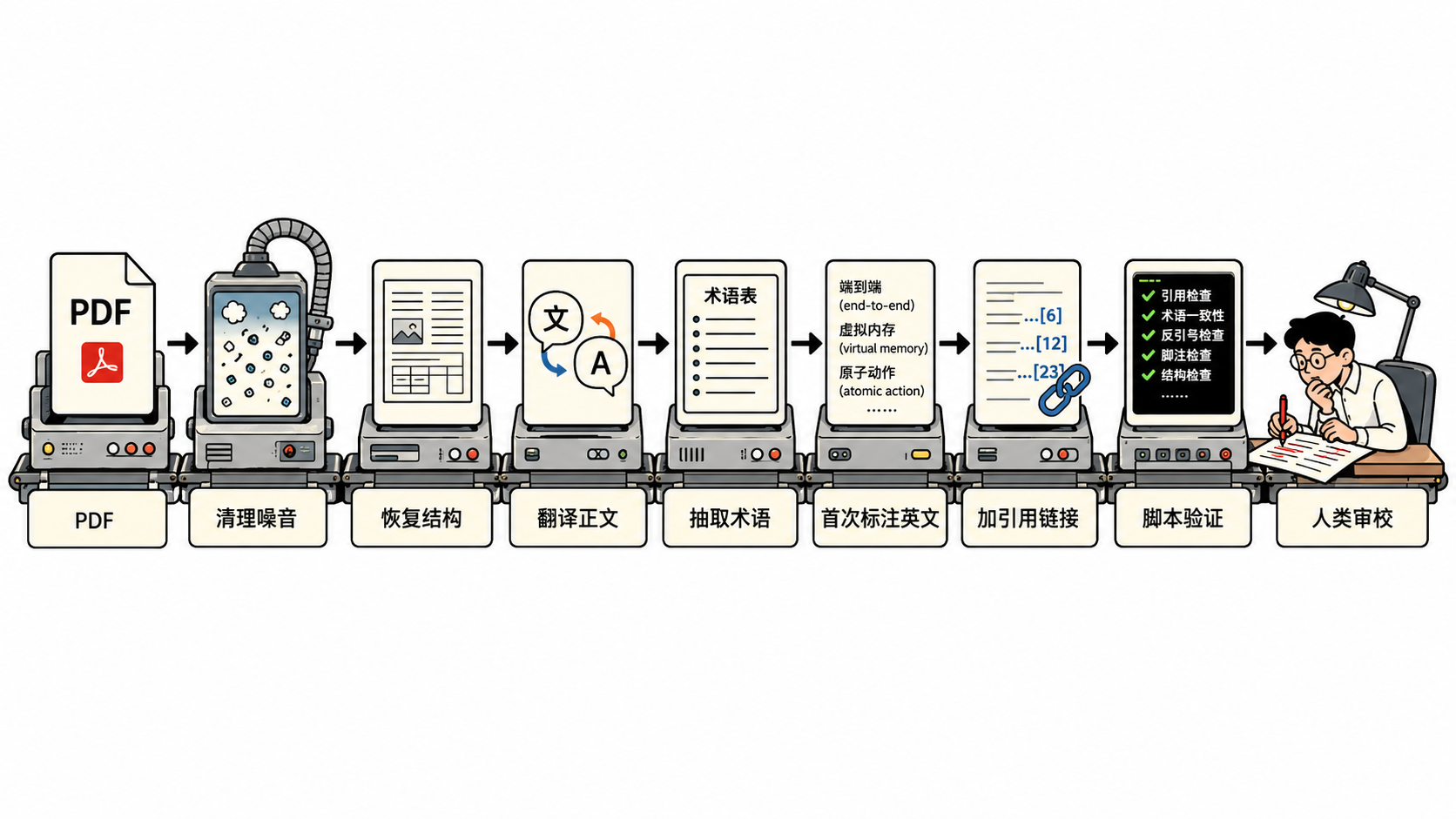
所以这次想试一下:能不能用 Codex 搭一条 agentic translating flow,把英文论文先转成一份可读、可改、可跳转的中文 Markdown。
第一篇选 Butler Lampson 的 Hints for Computer System Design。目标不是“一键翻译”,而是把任务拆开:PDF -> Markdown -> 翻译中文 -> 整理术语 -> 交叉引用 -> 验证。
最后整理出来的中文版在这里:《计算机系统设计箴言》。
数据
| 项目 | 数字 |
|---|---|
| 原始 PDF | 27 页 |
| 原始 Markdown | 556 行,约 13,853 个英文词 |
| 原文正文 | 约 12,961 个英文词 |
| References | 55 条,约 892 个英文词 |
| 中文 Markdown | 482 行,正文约 18,632 个汉字 |
| 正文引用链接 | 83 处 |
| 术语候选文件 | 333 行 |
| 术语检查报告 | 41 行 |
按文件时间戳看,从拿到原始 PDF 到生成审校后的中文 Markdown,约 56 分钟。从第一版原始 Markdown 到最终译文和术语报告,约 45 分钟。整个过程人类和 Codex 来回十几轮,其中真正改文件的大步骤大约 8 轮,用了大概 600k gpt-5.5 tokens。
如果换成真人技术译者,正文约 13,000 个英文词。熟悉计算机系统的人,初译可能要一周;加上 PDF 清理、图表重建、术语统一、引用处理和全篇审校,两周并不过分。如果译者不熟系统论文,只会更久。
对比起来,这次用 AI 不到一小时,而且还是第一次摸索流程。后面调通 agentic translating flow,PDF 抽取、术语表、引用修复、验证脚本都能复用,时间还会更少。
所以这次实验最明显的结论不是 AI 完美,而是成本结构变了。原本按“周”算的工作,被压到了按“小时”算。但质量和责任没有消失,只是转移到了流程设计、术语判断和最终审校。
原始 PDF 是文字型 PDF,不是扫描件。但 PDF 保存的是页面上的文字位置,不是文章结构。
所以第一步不是翻译,而是恢复结构。
编程工作都交给 Codex。它检查本地环境后选择用 PyMuPDF 抽取文本,生成原始 Markdown。文本出来后,仍然有页眉、页码、断行、乱掉的段落,以及被拆散的图 1。
图 1 是全文唯一的图,本质上是一张文本表格。Codex 把它重建成 Markdown table,并清理页眉、页码和段落断裂。
这一步的经验很简单:不要急着翻译。先把输入修到值得翻译。否则 AI 会把坏结构翻译成一份看起来更流畅的坏结构。
翻译与术语
正文交给 Codex 翻译,References 保留英文。要求是保住 Markdown 结构、代码片段、专有名词和引用编号。
真正麻烦的不是“英文变中文”,而是一致性。
比如 hint。标题里可以译成“箴言”,所以最后标题是《计算机系统设计箴言》。但正文技术语境里,它更接近系统给调用方或实现层的“线索”,所以技术概念统一成“线索”。
再比如 make actions atomic,最后用“使动作原子化”,比“使动作具备原子性”更直接。shed load 则从“舍弃负载”改成“削减负载”。
为了保证一致性,我让 Codex 先抽取术语候选。它生成了 333 行候选,然后我手动删掉过于普通或没必要标注英文的词。
最后保留的是会影响理解的术语,比如:
- 功能性(functionality)
- 容错性(fault-tolerance)
- 端到端(end-to-end)
- 虚拟内存(virtual memory)
- 原子动作(atomic action)
- 线索(hint)
这里真正麻烦的不是列术语,而是只在第一次出现时补英文,之后都用中文。
如果不做这一步,结果通常只有两个极端:要么满屏都是“中文(English)”,读起来像中英双语年报;要么完全没有英文原词,读者看到某个译名时只能倒猜作者原来写的是哪个词。
人工当然也能做,但很折磨。一个人要一路记住某个术语是不是第一次出现,基本等于在翻译时顺便扮演一个低配编译器,还不能崩溃。
规则最后变成:确实专业、可能歧义、保留英文有价值的术语,第一次出现时补英文。其他地方只保留中文。
引用
原文有大量参考文献。Markdown 支持 in-file anchor,所以正文里的 [6] 可以改成 [6](#ref-6),References 里对应加 <a id="ref-6"></a>。
我还把 References 改成真正连续的 numbered list,不再每条之间空一行。
脚注也处理了一次。原来有个 [^1],一开始想改成 [0],但放在标题后面不好看。最后把出版说明移回正文,去掉这处交叉引用。
引用处理很琐碎,但很重要。它决定读者能不能顺着正文跳到参考文献,而不是看到一堆无法点击的编号。
这事听起来麻烦,实际两轮 prompt 就搞定了。换成人工处理几十处引用、核对 55 条 References,至少半天起步,而且半天之后人的眼神通常已经不太适合从事精密劳动。
验证
长文本翻译不能只靠肉眼。
我让 Codex 配合脚本检查了几类问题:
- References 有没有被误翻
- 反引号数量是否平衡
- 每个 citation link 是否有对应 anchor
- 是否还有未链接引用
- 是否残留
[^1]或#ref-0 - 术语报告里是否还有“中文出现但英文没有”的候选词
人工审校也发现了一些模型和 PDF 抽取都容易漏掉的问题。
比如 PDF 抽取丢了上标,128 n/2 要改成 128^n / 2;O(n 2.5) 要改成 O(n^2.5)。Codex 甚至检查到了翻译后文中代码和数学表达式的正确性问题。还有 hint 的译法、[0] 引用是否保留,这些都需要人判断。
所以这个 flow 的核心不是“让 AI 翻译”,而是让 AI 进入一个可检查的流程。
这和 agentic coding 很像。以前最耗时的是编码,现在代码生成往往很快,真正麻烦的是 verification。agentic translating 也是这样:翻译本身反而很快,慢的是 PDF 结构恢复、术语一致性、引用完整性、以及最后确认它没有把一句话顺手翻错。
翻译要 G
这次实验不证明 AI 能完美翻译。但它说明,很多翻译工作会被重新定价。尤其是技术文档、内部资料、论文初译、字幕、说明书、客服知识库这类文本。
现在英文翻译 1000 字 60 元已经很低。按这篇正文约 13,000 个英文词算,人工翻译报价大概是几百到上千元量级。Codex 能把模型侧成本打到不到几块。哪怕把人的审校时间算进去,价格锚点也已经变了。

过去的流程是人慢慢翻。现在很可能变成:AI 初译,AI 整理术语,AI 补格式,AI 做检查,人类抽查、改关键处、承担责任。
翻译不会消失。但“逐句把英文搬成中文”的价值会大幅下降。译者会更像审校、编辑、领域顾问和责任签字人。
这也不只影响翻译。写初稿、资料整理、基础研究助理、报告润色、低阶代码搬运,都会遇到类似变化。
AI 不需要完整替代一个职业。它只要吃掉其中最稳定、最重复、最好计价的部分,剩下的岗位就会被重新定价。
对我来说,AI 不能替我理解 Lampson 的论文,但它能把原始 PDF 变成一份可读、可跳转、术语统一的中文 Markdown。
这大概就是我想要的结果:不是让 AI 替我读经典,而是让它把阅读之前那些机械、重复、耗时的工作先扫掉。
顺便一提,这篇文章也是 AI 读完 Codex 翻译 Session 后写出来的:
AI 帮我翻译论文,AI 帮我整理过程,AI 再帮我写一篇文章解释 AI 怎么帮我翻译论文。